mirror of
https://github.com/khoaliber/khoj.git
synced 2026-04-20 01:24:31 +00:00
These changes improve context available to the search model. Specifically this should improve entry context from short knowledge trees, that is knowledge bases with sparse, short heading/entry trees Previously we'd always split markdown files by headings, even if a parent entry was small enough to fit entirely within the max token limits of the search model. This used to reduce the context available to the search model to select appropriate entries for a query, especially from short entry trees Revert back to using regex to parse through markdown file instead of using MarkdownHeaderTextSplitter. It was easier to implement the logical split using regexes rather than bend MarkdowHeaderTextSplitter to implement it. - DFS traverse the markdown knowledge tree, prefix ancestry to each entry
![]()
![]()
![]()
![]()

An AI personal assistant for your digital brain
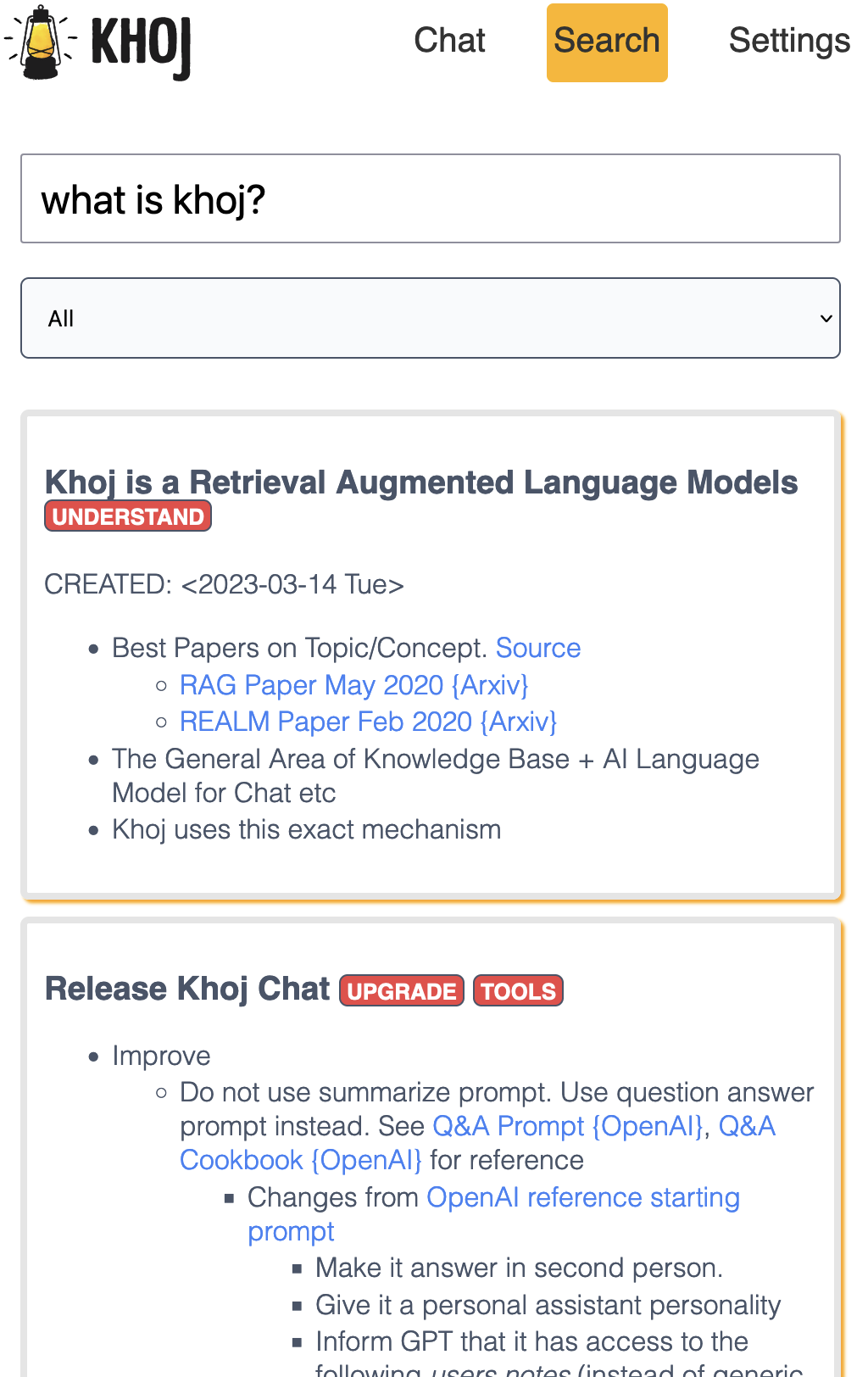
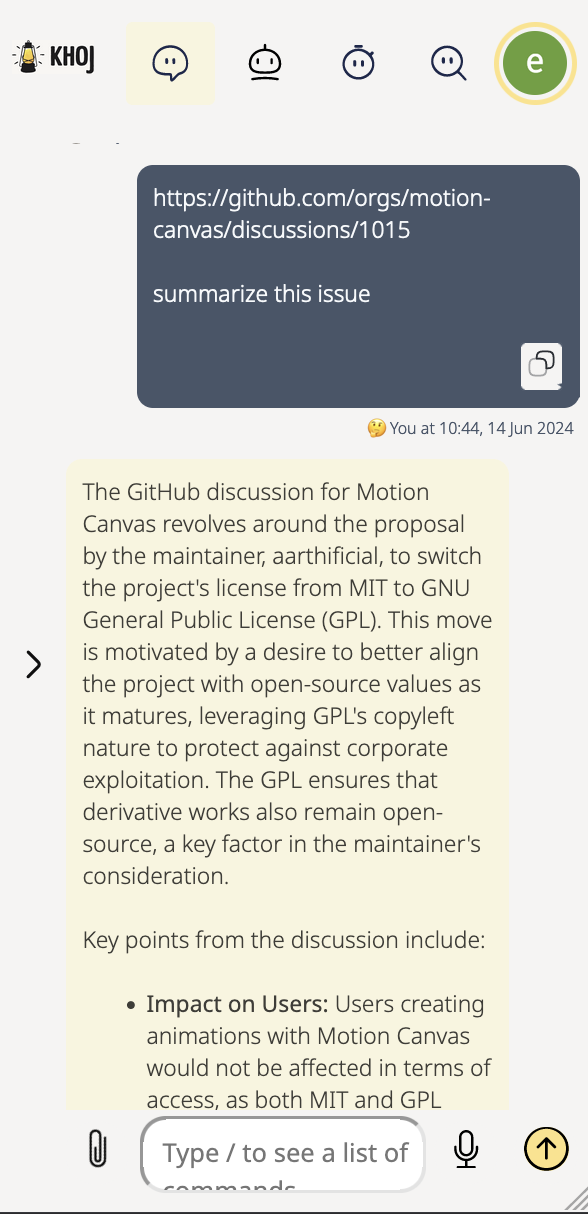
Khoj is an AI application to search and chat with your notes and documents.
It is open-source, self-hostable and accessible on Desktop, Emacs, Obsidian, Web and Whatsapp.
It works with pdf, markdown, org-mode, notion files and github repositories.
It can paint, search the internet and understand speech.
| 🔎 Search | 💬 Chat |
|---|---|
| Quickly retrieve relevant documents using natural language | Get answers and create content from your existing knowledge base |
| Does not need internet | Can be configured to work without internet |
 |
 |
Contributors
Cheers to our awesome contributors! 🎉
Made with contrib.rocks.