mirror of
https://github.com/khoaliber/khoj.git
synced 2026-03-03 21:29:08 +00:00
- Benefits of moving to llama-cpp-python from gpt4all:
- Support for all GGUF format chat models
- Support for AMD, Nvidia, Mac, Vulcan GPU machines (instead of just Vulcan, Mac)
- Supports models with more capabilities like tools, schema
enforcement, speculative ddecoding, image gen etc.
- Upgrade default chat model, prompt size, tokenizer for new supported
chat models
- Load offline chat model when present on disk without requiring internet
- Load model onto GPU if not disabled and device has GPU
- Load model onto CPU if loading model onto GPU fails
- Create helper function to check and load model from disk, when model
glob is present on disk.
`Llama.from_pretrained' needs internet to get repo info from
HuggingFace. This isn't required, if the model is already downloaded
Didn't find any existing HF or llama.cpp method that looked for model
glob on disk without internet
![]()
![]()
![]()
![]()

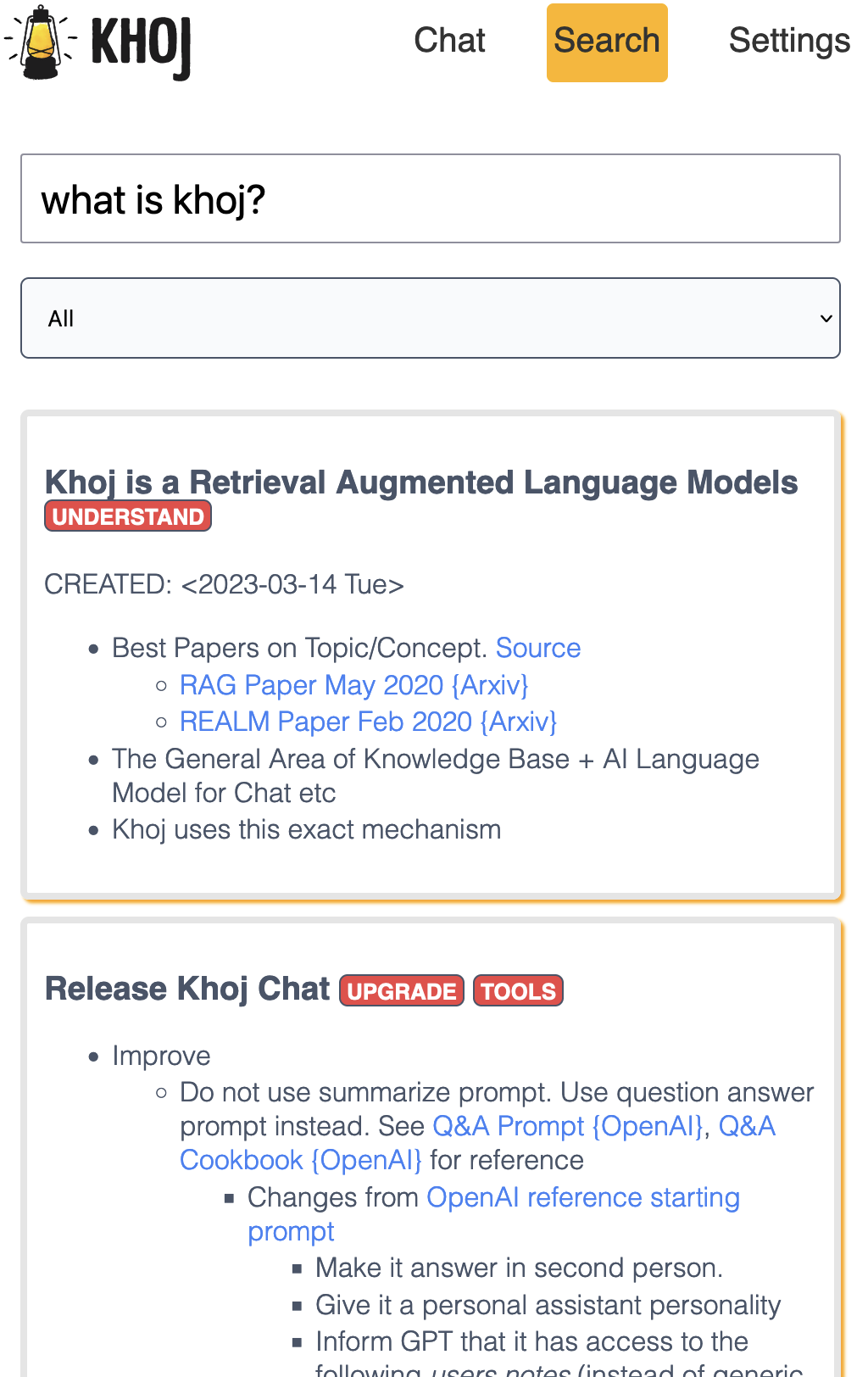
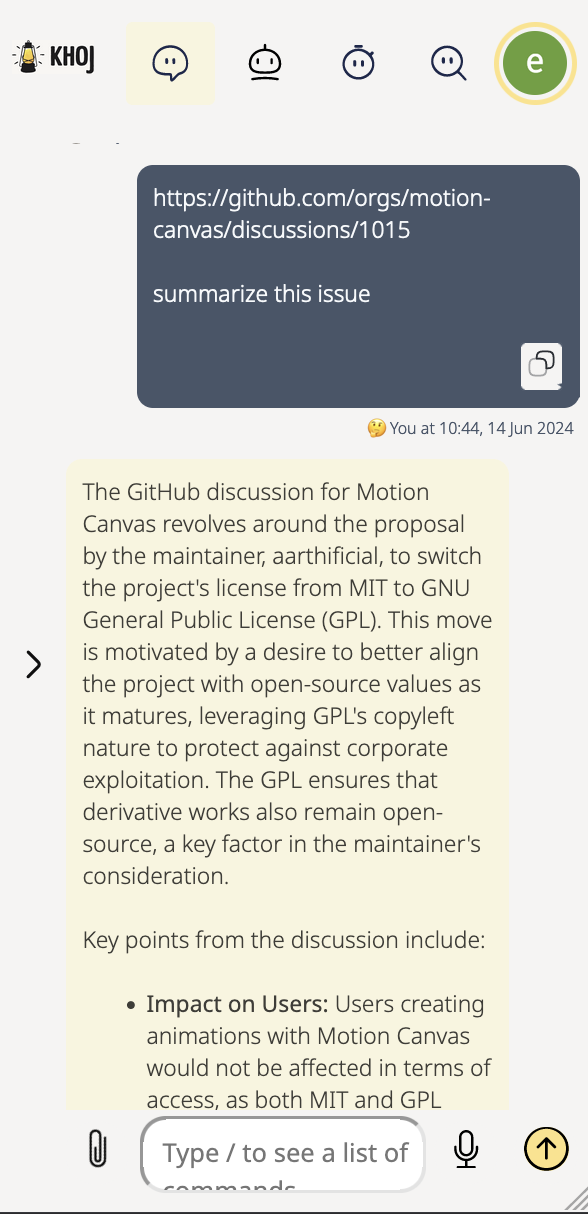
An AI personal assistant for your digital brain
Khoj is an AI application to search and chat with your notes and documents.
It is open-source, self-hostable and accessible on Desktop, Emacs, Obsidian, Web and Whatsapp.
It works with pdf, markdown, org-mode, notion files and github repositories.
It can paint, search the internet and understand speech.
| 🔎 Search | 💬 Chat |
|---|---|
| Quickly retrieve relevant documents using natural language | Get answers and create content from your existing knowledge base |
| Does not need internet | Can be configured to work without internet |
 |
 |
Contributors
Cheers to our awesome contributors! 🎉
Made with contrib.rocks.